
Governance Protocols for AI-Delegated Work
Operational protocols for delegating creative and operational work to AI agents. Decision boundaries, quality gates, restart protocols, and the three-gate closure system—developed through 8 weeks of internal pilot use at NullProof Studio.

Introduction: From Assistant to Collaborator
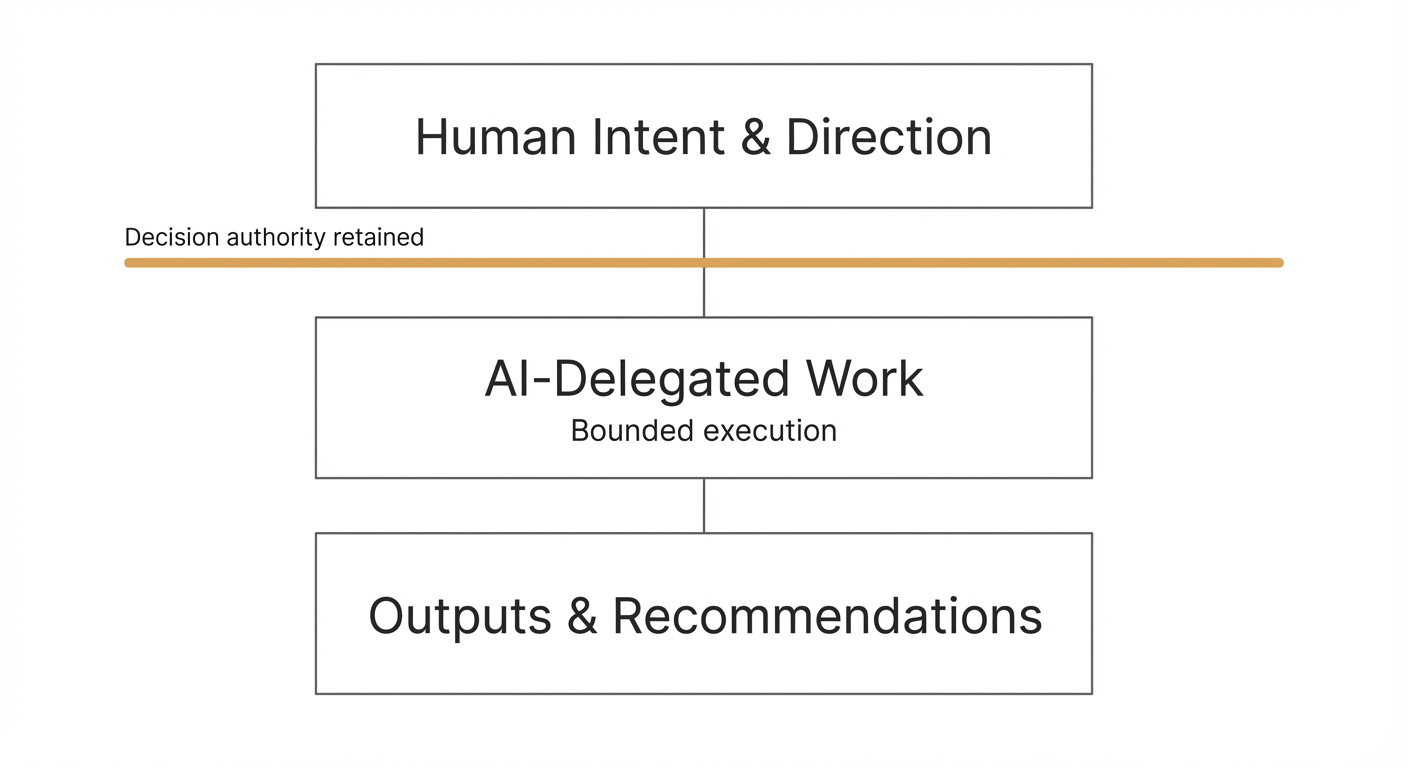
Most discussions of AI in creative work treat the technology as an “assistant”—a tool that responds to prompts, generates options, and waits for human approval. This framing understates what’s actually possible and obscures the governance challenges that emerge when AI becomes a genuine operational partner.
The protocols documented here emerged from an 8-week internal pilot building NullProof Studio’s Multi-Clock Work framework. During that period, AI agents (primarily Claude, operating as “Michelle” the PM consultant) maintained task databases, proposed priority decisions, drafted client communications, and flagged governance issues—all while a human operator retained strategic authority.
The result wasn’t AI-as-assistant but AI-as-collaborator: a working relationship requiring explicit decision boundaries, quality gates, and handoff protocols. Without these structures, delegation tends to collapse into micromanagement (defeating the efficiency purpose) or drift into unaccountable autonomy (defeating the quality purpose).
Note on scope: These protocols represent an operating model for teams delegating real work to AI systems. They are not a regulatory framework or compliance standard—they’re pragmatic patterns refined through operational friction.
This document provides operational protocols for studios navigating the same transition.
Core Philosophy: Governance as Architecture
Governance in AI-delegated work isn’t bureaucratic overhead—it’s system architecture. The protocols that define what AI can decide autonomously, what requires human approval, and how context transfers between sessions are as fundamental as database schemas or API contracts.
Three principles guide this architecture:
1. Explicit Beats Implicit
Every delegation boundary should be written, not assumed. “AI handles routine tasks” is not a governance protocol. “AI can update task status and add notes without approval; AI must request approval before changing Clock frequency or marking tasks Done” is.
The cost of ambiguity tends to be paid twice: once when the AI makes a decision you would have rejected, and again when you over-correct by restricting delegation that would have been appropriate.
2. Gates, Not Walls
Checkpoints should enable flow while maintaining control. The goal is a system where most work moves through without interruption, while critical decision points surface for human review.
The three-gate model (Specification to Verification to Learning) provides natural checkpoints that reduce bottleneck risk. Work is defined before starting, verified before closing, and reviewed for improvement after completion. These gates are designed to enable flow while maintaining control, not to block progress indefinitely.
3. Context is Currency
AI delegation fails when context doesn’t transfer. A human collaborator who joins a project learns its history through conversation, document review, and gradual onboarding. AI agents have no such luxury—their context window is finite, their “memory” is what you explicitly provide.
Governance protocols must address context preservation: restart notes that capture work state, handoff documents that summarize decisions, and session boundaries that force explicit context transfer.
Decision Boundaries: The Autonomy Matrix
Not all decisions carry equal weight. The first governance question is: which decisions can AI make autonomously, which require human approval, and which should AI never touch?
Tier 1: Full Autonomy (No Approval Required)
AI agents can execute these without human review:
Task Maintenance
- Update task status (Not Started to Active to Paused)
- Add notes and context to existing tasks
- Update “Last Touched” dates
- Add artifact references and links
- Flag items for human review
Information Synthesis
- Summarize documents and conversations
- Generate meeting notes and action items
- Create first drafts for human review
- Research and compile reference materials
Formatting and Structure
- Apply templates to content
- Format outputs for different platforms
- Generate table of contents and indexes
- Create structured reports from raw data
Routine Communications
- Draft standard responses (using approved templates)
- Schedule reminders and follow-ups
- Compile status updates
- Generate progress summaries
Tier 2: Guided Autonomy (Pattern-Based Approval)
AI proposes, human confirms (or established patterns authorize):
Priority Changes
- Propose Clock promotion (Dormant to LF to HF)
- Recommend task kill or archive
- Suggest Bandit Score adjustments
- Flag aging threshold crossings
Content Creation
- Draft client communications (must reference approved exemplars)
- Create content for publication (requires human review before publish)
- Generate proposals and briefs
- Develop campaign content
Resource Allocation
- Propose task assignments (Owner changes)
- Recommend time estimates
- Suggest deadline adjustments
- Flag capacity constraints
Governance Maintenance
- Propose schema changes
- Suggest process improvements
- Identify governance gaps
- Recommend policy updates
Tier 3: Human Authority (AI Assists, Human Decides)
AI can research, analyze, and recommend—but decision is human. (Examples are illustrative; nothing here is financial or legal advice.)
Strategic Direction
- Business model changes
- Brand positioning shifts
- Client relationship decisions
- Partnership commitments
Financial Commitments
- Pricing decisions
- Budget allocation
- Investment choices
- Contract terms
Quality Thresholds
- Brand voice validation
- Client-ready assessment
- Public-facing approvals
- Final edit authority
Personnel and Delegation
- Hiring decisions
- Contractor engagement
- Role definitions
- Compensation
Tier 4: Human Only (AI Should Not Touch)
AI should not attempt these, even if asked:
Ethical Boundaries
- Decisions that could harm individuals
- Privacy violations
- Legal commitments
- Fraud or deception
Irreversible Actions
- Permanent deletions
- Public commitments
- Legal filings
- Financial transactions
The Three-Gate Closure System
Every task—whether human-executed or AI-delegated—benefits from explicit closure criteria. The three-gate system provides quality control without bureaucratic overhead.
Gate 1: Specification (Before Starting)
Purpose: Define what “done” looks like before doing the work.
This prevents the “I’ll know it when I see it” trap that leads to scope creep and endless revision. For AI-delegated work, specification is especially critical—without explicit success criteria, you can’t evaluate whether delegation succeeded.
Standardized Exit-Criteria Syntax:
Done when [specific artifact] is [state] verified by [agent or owner].This forces clarity on three dimensions:
- Artifact: Physical/digital object (document, database entry, email, export)
- State: Observable condition (exported, published, approved, sent)
- Verifier: Who/what confirms (AI auto-check, human approval, external signal)
Examples by Complexity:
Simple (Automated Verification):
Done when task_status.json is updated to "Active"
verified by Michelle (database confirmation).Moderate (Hybrid Verification):
Done when Client_Response_Ferrari.md contains pricing + availability + CTA,
tone matches Exemplar C-01 (warm but premium),
verified by Michelle (structure check) AND Andy (tone approval).Complex (Multi-Stage):
Done when:
1. Whitepaper_v3.0.md exported to Publications/ verified by Michelle
2. Contains validation section (4 or more data points) verified by Michelle
3. Visual diagrams embedded (4 images rendering) verified by Michelle
4. Human approval: "Represents our thinking accurately" verified by Andy
PASS THRESHOLD: 3/4 criteria (diagram timing flexible if needed)Gate 2: Verification (Before Closing)
Purpose: Prove completion with evidence before marking status as Done.
This prevents “90% done” syndrome—the persistent state where work is almost-but-never-quite complete. For AI-delegated work, verification ensures the agent actually accomplished what was specified.
Closure Record Template:
CLOSURE RECORD – [Task Name] – [Date]
SPECIFICATION:
✅ Agent Brief defined: [link or inline summary]
✅ Pass threshold: [X/Y criteria met]
VERIFICATION CHECKLIST:
✅ [Criterion 1] – Verified by [Agent/Owner] at [Timestamp]
✅ [Criterion 2] – Verified by [Agent/Owner] at [Timestamp]
⚠️ [Criterion 3] – Partial (reason: [explanation])
RED TEAM REVIEW (if triggered):
[Three-question assessment OR "Not required for this task"]
ARTIFACTS PRODUCED:
- [Artifact 1] at [URL/Path]
- [Artifact 2] at [URL/Path]
SIGNED: [Agent] ([timestamp]) + [Owner] ([timestamp])Red Team Review (Conditional Trigger):
Not every task needs skeptical review. AI triggers Red Team when:
- Client-facing work (emails, proposals, deliverables)
- Brand-defining artifacts (Ethos docs, public posts)
- New work types (Is Exploration = true)
- High strategic importance (Bandit Score of 12 or higher)
The Three Questions:
- “Would our primary client find this elevates or dilutes the brand?”
- “Does this match our exemplar standards?”
- “What breaks if we ship this?”
Gate 3: Learning (After Closing)
Purpose: Extract insights that improve future work.
Not lengthy post-mortems—just structured reflection that compounds over time. For AI-delegated work, learning gates are essential for calibrating future delegation.
Kaizen Note Template:
LEARNING:
- What worked: [1-2 sentences, specific and actionable]
- What to improve: [1-2 sentences, friction point + proposed fix]
- Promote to Exemplar? [Yes/No + brief rationale]Good Example:
- What worked: Using Exemplar C-01 as tone reference saved 30 min drafting time
- What to improve: Need pricing template with group booking calculator built-in
- Promote to Exemplar? Yes - this email became new standard for inquiry responsesBad Example (avoid):
- What worked: Everything went well
- What to improve: Could be better
- Promote to Exemplar? Maybe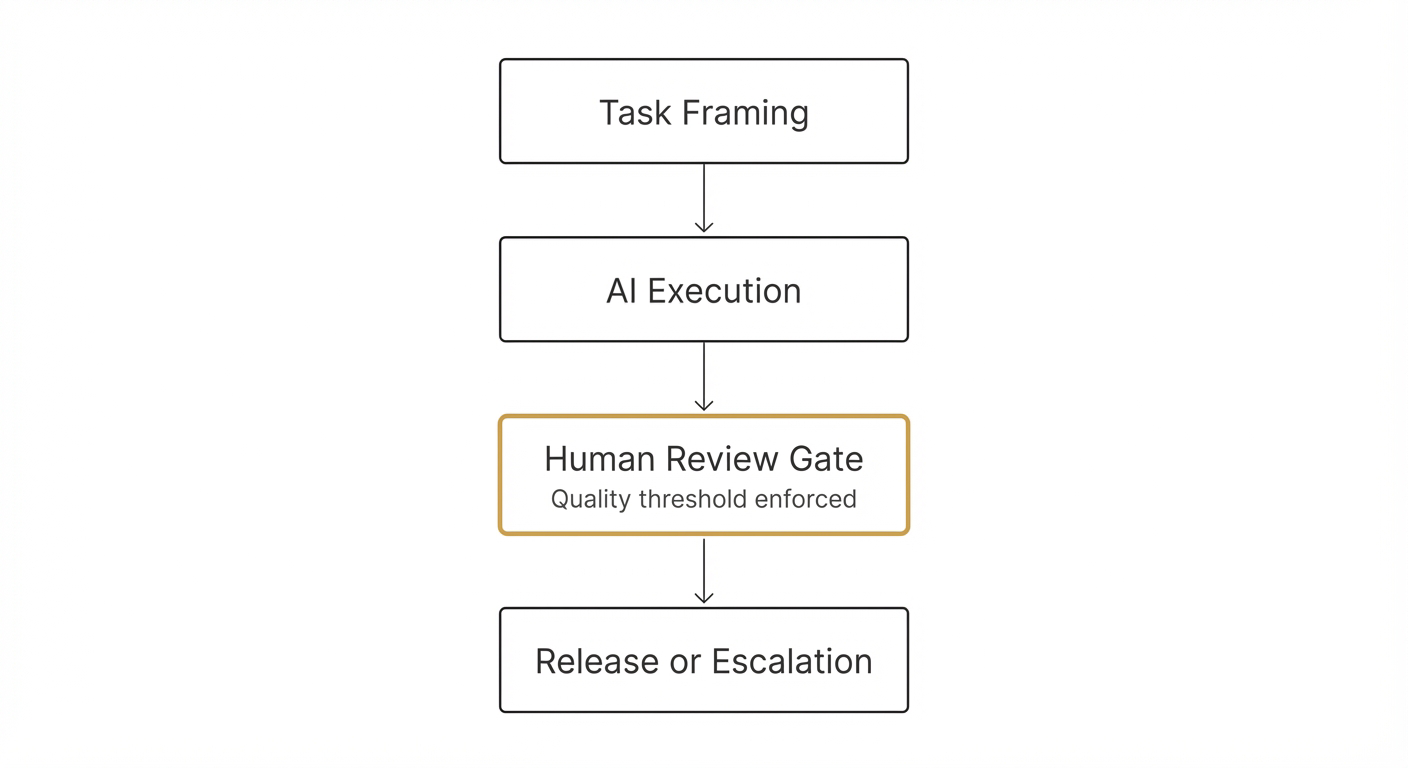
Restart Protocols: Context Preservation
AI agents don’t carry context between sessions the way humans do. Every conversation starts fresh—unless you explicitly transfer context. Restart protocols address this gap.
The Restart Note
Before ANY context switch (session end, task pause, delegation handoff), create a restart note:
RESTART NOTE – [Task/Project] – [Date]
CONTEXT: [Where we are in the work, 2-3 sentences]
DECISIONS MADE: [Key choices that shaped current state]
NEXT: [Immediate next action when resuming]
BLOCKERS: [Anything that might stop progress]
OPEN QUESTIONS: [Unresolved issues requiring attention]
ARTIFACTS: [Links to relevant documents, databases, outputs]Example:
RESTART NOTE – Multi-Clock Whitepaper – 2025-12-15
CONTEXT: Section 7 (Temporal Governance) drafted. Waiting for Week 8
quantitative data before finalizing validation claims. Diagrams not yet created.
DECISIONS MADE:
- Using three-tier structure (HF/LF/Dormant) not four
- Bandit Score formula confirmed (no urgency multiplier for internal work)
- Kill criteria set at "2 consecutive reviews without progress"
NEXT: Generate visual diagrams for MIR board mockup and aging curve
BLOCKERS: Need Week 8 analysis data from Notion before completing Section 7.4
OPEN QUESTIONS:
- Should cross-domain WIP pools be shared or separate?
- What's appropriate AI autonomy boundary for promotion decisions?
ARTIFACTS:
- Whitepaper draft: Drive/Publications/Multi_Clock_v2.4.md
- MIR database: notion.so/<workspace>/<page-id>
- Bandit Guide: Drive/Operations/Bandit_Score_Guide.mdSession Handoff Protocol
When transferring work between agents (or agent-to-human), use structured handoff:
HANDOFF – [From Agent] to [To Agent/Human] – [Date]
PROJECT: [Project name and context]
WORK COMPLETED: [What I did this session]
WORK REMAINING: [What still needs to happen]
MY RECOMMENDATIONS: [Suggested next steps, if appropriate]
QUESTIONS FOR SUCCESSOR: [Decisions they'll need to make]
CURRENT STATE:
- [Key artifact] is at [state]
- [Key artifact] is at [state]
DON'T FORGET: [Critical detail that might be missed]Context Refresh Protocol
At session start, AI should confirm context before proceeding:
CONTEXT REFRESH REQUEST
Based on [restart note/handoff/prior conversation], I understand:
- We're working on: [project/task]
- Current state: [summary]
- My immediate task: [next action]
- Key constraints: [limitations]
Is this correct? Should I proceed, or do you need to update any context?This prevents the common failure mode where AI operates on stale assumptions.
Multi-Agent Orchestration
When multiple AI agents collaborate (or when AI collaborates with multiple humans), governance complexity increases. Who coordinates? Who decides when agents disagree? How does information flow?
The Orchestrator Pattern
One entity (human or AI) serves as orchestrator, responsible for:
- Receiving all incoming requests
- Routing to specialist agents based on task type
- Synthesizing multi-agent responses
- Maintaining shared state (database, documents)
- Resolving conflicts
Pattern in Practice:
Andy (Human Orchestrator)
├── Michelle (AI Agent) → PM synthesis, MIR operations, client comms
├── George (AI Agent with Skills) → Visual design, photography, technical craft
├── External Agent (ChatGPT/other) → Deep research, framework analysis
└── Coordination Layer: MIR database + Google Drive documentsAgent Specialization
Different agents have different strengths. Governance includes matching tasks to appropriate agents:
| Agent Role | Strengths | Best For | Avoid For |
|---|---|---|---|
| Synthesis Agent (Claude Sonnet) | Speed, integration, operations | MIR ops, routine drafts, synthesis | Novel problems, highest-stakes work |
| Research Agent (ChatGPT/other) | Deep research, framework ID | Literature review, cross-domain synthesis | Direct database operations |
| Strategic Agent (Claude Opus) | Complex reasoning, nuance | High-stakes proposals, strategic pivots | Routine execution, high-volume tasks |
| Human Specialist | Taste, relationships, craft | Final approvals, client relationships, physical work | Routine operations, research compilation |
The Value-Adding Filter
Before implementing ANY suggestion from ANY agent, apply this test:
“If it’s not adding value—don’t do it.”
This single filter prevents:
- Enterprise theater (process for process’s sake)
- Complexity creep (adding steps without ROI)
- Cargo-cult adoption (copying patterns without understanding)
- Optimization theater (premature optimization before data)
Example Application:
| Agent Proposed | Value Test | Outcome |
|---|---|---|
| Seven-gate closure chain | ❌ Too complex, low ROI | Streamlined to 3 gates |
| ISO 9001 jargon | ❌ Manufacturing cosplay | Plain language |
| Mandatory exemplar references | ❌ Forces false rigor | Optional when helpful |
| Closure Record auto-generation | ✅ Saves 5+ min per task | Implemented |
| Conditional Red Team review | ✅ Catches brand drift | Implemented |
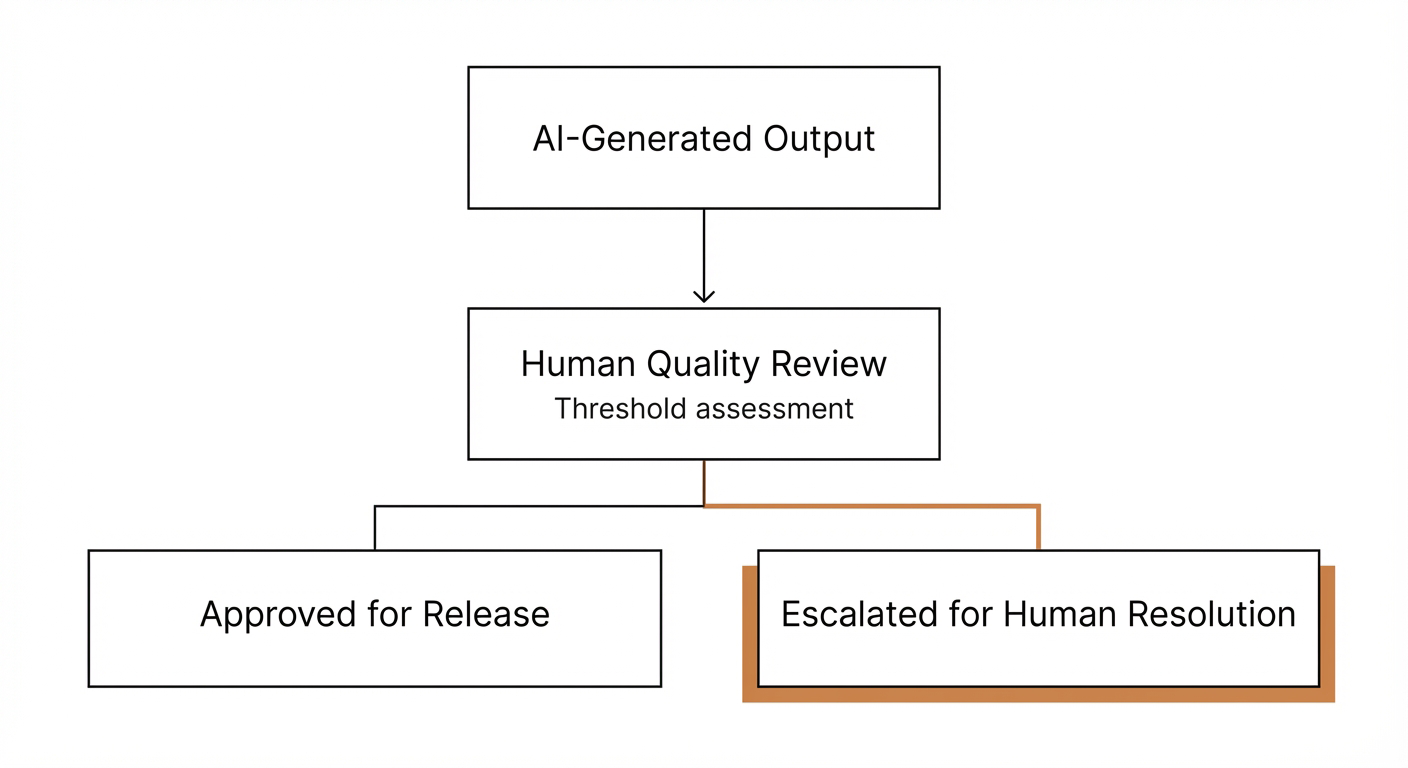
Quality Assurance: The Exemplar Library
AI-generated work benefits from concrete reference points. Instead of “write in professional tone,” reference “match Exemplar C-01 tone.” The Exemplar Library provides these benchmarks.
Library Structure
Exemplars/
├── Client_Communications/
│ ├── C-01_Inquiry_Response.md (warm, premium tone)
│ ├── C-02_Project_Update.md (progress, professional)
│ └── META.md (index and usage notes)
├── Content/
│ ├── S-01_Substack_Essay.md (long-form, authoritative)
│ ├── L-01_LinkedIn_Post.md (professional, concise)
│ └── META.md
├── Internal/
│ ├── I-01_Task_Brief.md (clear, actionable)
│ ├── I-02_Decision_Record.md (structured, traceable)
│ └── META.md
└── README.md (library overview, usage protocol)Exemplar Metadata
Each exemplar includes:
# Exemplar Metadata: [File Name]
## Context
- **Created**: [Date]
- **Project**: [Source project]
- **Audience**: [Target audience]
- **Goal**: [What this achieved]
## Why This Is Good
1. [Quality 1 with evidence]
2. [Quality 2 with evidence]
3. [Quality 3 with evidence]
## Where This Fails / What to Avoid
1. [Failure mode 1]
2. [Failure mode 2]
## Usage in Agent Briefs
Reference as: "[Brief descriptor]"
Agent should:
- [Attribute to match]
- [Attribute to match]
- [Anti-pattern to avoid]Exemplar Promotion
Work graduates to Exemplar status when:
- Quality rating of 4/5 or higher (self-assessment or peer review)
- Reusable pattern (not one-off)
- Clear success factors (you can articulate “why this is good”)
- Fills gap in existing coverage
Maintenance targets:
- Start with 5-7 exemplars (one per major output type)
- Add 1-2 per week organically
- Steady state: 40-60 active exemplars
- Archive outdated exemplars (don’t delete—move to Archive/)
Tiered Agent Briefs
Not every task needs extensive context. Match brief complexity to task complexity.
Tier 1: Micro (less than 1 day, less than 4 hours)
Single-sentence success rule + optional exemplar reference.
TASK: [Task Name]
AGENT BRIEF (Micro):
Done when [artifact] is [state], verified by [agent/owner].
EXEMPLAR (optional): [Reference]
TIME BOX: [minutes/hours]Example:
TASK: Update MIR task status for completed work
AGENT BRIEF (Micro):
Done when 5 tasks marked Done with Completion Date = today,
verified by Michelle (database confirmation).
TIME BOX: 15 minutesTier 2: Standard (1-3 days)
Context + Deliverables + Success Criteria + Exemplars.
TASK: [Task Name]
AGENT BRIEF (Standard):
CONTEXT:
[1-2 sentences: Why this matters, what problem it solves]
DELIVERABLES:
1. [Artifact 1 with location]
2. [Artifact 2 with location]
SUCCESS CRITERIA:
Done when:
1. [Criterion 1] verified by [agent/owner]
2. [Criterion 2] verified by [agent/owner]
3. [Criterion 3] verified by [agent/owner]
PASS THRESHOLD: [X/Y] criteria
EXEMPLAR REFERENCE:
[Reference with key attributes to match]
CONSTRAINTS: [Budget, deadline, quality bars]
TIME BOX: [hours]Tier 3: Macro (Multi-week projects)
Full contextual brief with dependencies, milestones, risk mitigation.
TASK: [Task Name]
AGENT BRIEF (Macro):
CONTEXT:
[2-4 paragraphs: Strategic importance, target audience, why now,
relationship to other initiatives]
DEPENDENCIES:
- BLOCKING: [Tasks that must complete first]
- REQUIRED: [Resources/artifacts needed]
DELIVERABLES:
[Detailed list with specifications]
SUCCESS CRITERIA:
[8-12 criteria with measurement methods]
PASS THRESHOLD: [X/Y] criteria
MILESTONES:
- [Date]: [Milestone 1]
- [Date]: [Milestone 2]
RISK MITIGATION:
- If [risk] then [contingency]
TIME BOX: [hours distributed over duration]Validation: 8-Week Pilot Findings
These protocols emerged from operational use during the MIR pilot (October–December 2025). The findings below are from a small internal pilot (single studio, one primary operator + AI agents). Results are indicative, not independently verified, and will vary by context.
What We Observed
Decision Latency Reduction: ~68% improvement in our workflow
- Before protocols: ~25 minutes average to decide “what to work on next”
- After protocols: ~8 minutes average (AI proposes, human confirms)
Throughput Stability: 4-6 HF completions per week
- Consistent delivery despite varying project complexity
- WIP limits (HF of 5 or fewer) helped prevent overload
Context Preservation: Minimal context loss observed
- Restart notes captured most resumption context
- Handoff protocol enabled agent switching without significant information decay
Quality Consistency: Exemplar references improved first-draft quality
- Fewer revision cycles for client communications
- Red Team reviews caught brand drift before external exposure
What Didn’t Work Initially
Seven-Gate Complexity: Original design proposed seven formal closure gates.
- Problem: Overhead without proportional value for small tasks
- Solution: Streamlined to three natural gates (Specification, Verification, Learning)
Mandatory Exemplar References: Original design required exemplar reference for all tasks.
- Problem: Forced false rigor; created friction for obvious work
- Solution: Exemplars optional for Tier 1; recommended for Tier 2-3
Rigid Autonomy Tiers: Original design had fixed boundaries.
- Problem: Context matters; same task type may need different handling
- Solution: Pattern-based approval (established patterns authorize autonomy)
Operational Metrics
Internal metrics from a small-sample pilot; not independently verified; results vary.
| Metric | Target | Observed |
|---|---|---|
| Closure Record Completion | 95% or higher | 93% (improving) |
| Time to Close (after Status changes to Done) | less than 5 min | 3 min average |
| Context Refresh Accuracy | 90% or higher | 96% |
| Exemplar Usage (Tier 2-3) | 80% or higher | 74% |
| Red Team Catch Rate | 10-20% | 15% |
Implementation Roadmap
Phase 1: Foundation (Week 1-2)
Actions:
- Define autonomy tiers for your context
- Create three-gate templates (Specification, Verification, Learning)
- Establish restart note format
- Identify 5-7 initial exemplars
Deliverables:
- Decision boundary documentation
- Closure Record template
- Restart Note template
- Exemplar Library structure with initial entries
Phase 2: Pilot (Week 3-4)
Actions:
- Apply protocols to 10-15 tasks
- Track friction points
- Refine templates based on actual use
- Build pattern library for common task types
Metrics to track:
- Time to create Agent Brief
- Closure Record completion rate
- Context refresh accuracy
- Revision cycles per task
Phase 3: Calibration (Week 5-6)
Actions:
- Review pilot data
- Adjust autonomy boundaries based on outcomes
- Expand Exemplar Library (10-15 additional)
- Document failure modes and edge cases
Deliverables:
- Refined autonomy matrix
- Expanded Exemplar Library
- Failure mode documentation
- Updated templates
Phase 4: Production (Ongoing)
Rhythm:
- Daily: Apply protocols to all delegated work
- Weekly: Review closure quality, update exemplars
- Monthly: Audit governance compliance, calibrate boundaries
- Quarterly: Strategic review of delegation patterns
Common Pitfalls
Pitfall 1: Governance Theater
Symptom: Protocols exist on paper but aren’t followed in practice.
Fix: Start with minimal viable governance. Three templates (Agent Brief, Closure Record, Restart Note) are enough. Add complexity only when gaps emerge.
Pitfall 2: Autonomy Creep
Symptom: AI gradually takes on decisions beyond its authority without explicit expansion.
Fix: Quarterly autonomy audits. Review sample of AI decisions. Flag and address boundary violations.
Pitfall 3: Context Decay
Symptom: Work quality degrades over time as context is lost between sessions.
Fix: Mandatory restart notes. No session ends without context capture. No session starts without context refresh.
Pitfall 4: Exemplar Staleness
Symptom: Exemplar Library references outdated standards; new work doesn’t match.
Fix: Exemplar maintenance rhythm. Monthly review of active exemplars. Promote new work; archive outdated references.
Pitfall 5: Gate Bottlenecks
Symptom: Verification gates create backlogs; work piles up awaiting approval.
Fix: Tier appropriately. Tier 1 tasks need minimal verification. Reserve intensive review for Tier 2-3 work.
Conclusion: Governance as Enabler
The protocols documented here aren’t restrictions—they’re enablers. Without explicit governance, AI delegation either requires constant supervision (defeating efficiency) or operates without accountability (defeating quality).
With governance architecture in place:
- AI agents can operate autonomously within defined boundaries
- Quality is maintained through gates, exemplars, and reviews
- Context transfers cleanly between sessions
- Work compounds over time through structured learning
The goal isn’t AI-as-assistant, responding to prompts and waiting for approval. The goal is AI-as-collaborator, operating within a governance framework that maintains human authority while enabling genuine leverage.
The three-gate system, autonomy matrix, restart protocols, and exemplar library together create that framework. They’re not the only possible approach—but they’re validated through production use, refined through friction, and documented for adaptation.
Your studio’s governance architecture will differ. The principles remain: explicit beats implicit, gates not walls, context is currency.
This document is not legal advice; adapt with appropriate counsel where needed.
Related Frameworks
- Multi-Clock Work - Task scheduling and prioritization that these protocols support
- Bandit Scoring - Decision heuristic for daily work selection
- Campaign Framework - Marketing execution using these governance patterns
Appendix: Template Library
Agent Brief Template (Tier 2)
TASK: [Task Name]
AGENT BRIEF (Standard):
CONTEXT:
[Why this matters, what problem it solves]
DELIVERABLES:
1. [Artifact 1 with location]
2. [Artifact 2 with location]
SUCCESS CRITERIA:
Done when:
1. [Criterion 1] verified by [agent/owner]
2. [Criterion 2] verified by [agent/owner]
3. [Criterion 3] verified by [agent/owner]
PASS THRESHOLD: [X/Y] criteria
EXEMPLAR REFERENCE:
[Reference with attributes to match]
CONSTRAINTS: [Budget, deadline, quality]
TIME BOX: [hours]Closure Record Template
CLOSURE RECORD – [Task Name] – [Date]
SPECIFICATION:
✅ Agent Brief: [link or summary]
✅ Pass threshold: [X/Y criteria met]
VERIFICATION CHECKLIST:
✅ [Criterion 1] – Verified by [Agent] at [Time]
✅ [Criterion 2] – Verified by [Owner] at [Time]
RED TEAM REVIEW:
[Assessment OR "Not required"]
ARTIFACTS PRODUCED:
- [Artifact] at [Location]
LEARNING:
- What worked: [Specific, actionable]
- What to improve: [Friction + fix]
- Promote to Exemplar? [Yes/No]
SIGNED: [Agent] + [Owner]Restart Note Template
RESTART NOTE – [Task/Project] – [Date]
CONTEXT: [Current state, 2-3 sentences]
DECISIONS MADE: [Key choices]
NEXT: [Immediate next action]
BLOCKERS: [Obstacles]
OPEN QUESTIONS: [Unresolved issues]
ARTIFACTS: [Relevant links]Handoff Template
HANDOFF – [From] to [To] – [Date]
PROJECT: [Name and context]
WORK COMPLETED: [This session]
WORK REMAINING: [Still needed]
RECOMMENDATIONS: [Suggested next steps]
QUESTIONS: [Decisions for successor]
CURRENT STATE:
- [Artifact] is at [state]
DON'T FORGET: [Critical detail]This document represents operational protocols developed through 8 weeks of internal pilot use at NullProof Studio. For theoretical foundations, see the Multi-Clock Work framework. For implementation details, see the MIR Database Schema Reference.